tidyverse有两层基本含义:(1)基于Google 社区的R 代码风格(Google’s R style guide)衍生的一种使代码清晰可读的编程风格;(2)一系列基于前述风格而编写的数据处理R 包。tidyverse一词中的tidy意为整洁,verse意为诗篇、诗行,合起来意指代码或数据如诗行般整洁易读,即成为“整洁代码”(tidy code)或“整洁数据”(tidy data)。熟悉这一风格和相关R 包,可使数据处理和代码编写过程更为便捷高效,且易于与其他数据分析者交流沟通。
建立较为统一的代码书写风格,可方便不同用户之间的沟通与协作。这里基于tidyverse模式择要介绍目前R 编程中的主流风格,并根据中文用户的习惯做部分调整和说明。某些内容可能初学者并不一定很快遇到,但仍宜先行阅读,以建立良好的书写规范。详细的tidyverse风格说明参见如下链接:
三、命名规范
1.文件名
文件名应能体现文件的实质内容,只使用数字、英文字母、中划线-和下划线_。尽量避免文件名中的英文字母大小写混用,宜只使用小写,并建议使用_或-连接文件名中的不同英文,如nankai_psy_2017。
若多个文件存在特定顺序,应以数字作为前缀。如果有超过10个文件,对于个位数的前缀要在前面添补一个0。例如:

其中,.后的xx表示适当的文件后缀名,可能是csv、xlsx、pdf、png等。
超过100个文件则在最开始补充00,依此类推。
2.变量与函数名
变量和函数名应只使用小写字母、数字和下划线_。下划线(_)用于分隔较长命名中的不同单词,避免用.分隔。例如,变量名写成bmi_women,而不是bmi.women;函数名写成trim_gini,而不是trim.gini。变量名应是名词,而函数名应是动词,且应尽量简洁。
这里和base R可能有些区别
在标识符中不要使用下划线 (
_) 或连字符 (-). 标识符应根据如下惯例命名. 变量名应使用点 (.) 分隔所有的小写字母或单词; 函数名首字母大写, 不用点分隔 (所含单词首字母大写); 常数命名规则同函数, 但需使用一个k开头.variable.name正例:avg.clicks反例:avg_Clicks,avgClicksFunctionName正例:CalculateAvgClicks反例:calculate_avg_clicks,calculateAvgClicks函数命名应为动词或动词性短语. 例外: 当创建一个含类 (class) 属性的对象时, 函数名 (也是constructor) 和类名 (class) 应当匹配 (例如, lm).kConstantName
我自己日常更多是类似于tidy风格。
3.赋值
尽量使用<-而不是=进行对象赋值。
=号宜只用于参数传递。
四、写作语法
1.空格
汉语写作中基本无须注意空格,但在英文书写和编程中正好相反。在适当的地方插入空格,可使文本和代码整洁美观,务必引起重视。
=、+、-、<-这四个符号两侧需要有一个空格。与正常英文书写一样,逗号后面(而不是前面)应有空格。
但是,:、::和:::两侧不需要空格。

小括号(的前面需要加空格,调用函数时除外。
若为对齐=号或赋值符号<-,可使用多个空格。

2.缩进
通常不用制表符(Tab 键)进行缩进,用两个空格进行缩进。
花括号{}用于定义R 代码中的层级。{}内的每行代码前应缩进两个空格。大括号的左半边{不能独占一行,其后应另起一行。右半边}应独占一行,除非后面有else或)。

若if语句非常简单,仅占一行,可不使用花括号。例如:

3.行宽
每行代码宜不超过80个字符。若代码超出这一长度,应尽量将一些功能打包成独立的函数。
若代码太长,不能写成一行代码,可以一行写函数名,一行写参数,一行写右括号)。这样代码可读性更强,也便于修改。例如:

若参数之间关系密切,可以将几个参数放在同一行中,例如用paste()或stop()调用字符串。如有可能,生成字符串时要将一行代码和它的输出放到同一行中。
不要把分号;放在行尾,也不要用它分隔同一行的多条命令。
4.管道操作
当将三个或更多的函数嵌套调用,或者创建无须关心的中间对象时,要使用管道操作符:%>%,其含义是将上一个函数的结果传递作为下一个函数的第一个参数。%>%的前面应有一个空格,后面的代码应另起一行。若一个函数的所有参数不能同时在一行中,则在每行放置一个参数并且缩进。完成第一步后,每一行都应缩进两个空格。即使某一步的管道操作可以省略对象,也应在函数名后加上()。参见如下示例:


如果需要操纵不止一个对象,或者中间对象具有实际意义且后面需要加以调用时,应避免使用管道操作。虽然在管道操作的最后可用->赋值,但应尽量避免这一做法,以增加代码的可读性。
5.注释
每行注释都以#号开始,#号后需要加一个空格。
可使用由-和=构成的注释行将文件分割成容易理解的段落。

五、tidyverse 包简介
作为R 包的tidyverse 集合了当下最为流行的数据处理包,是简化数据操纵、便利统计操作、美化结果呈现的高效工具。
1.基本理念
整洁数据是Hadley 等人极力提倡的一个数据处理理念。若要执行统计计算,统计软件对数据格式有一定要求。但通常外部导入的数据并不一定能达到软件处理的要求,而需要进行一定的预处理,此过程通常也称为数据清洗(data cleaning)。实际上,这种前期处理的工作往往占据比狭义的统计分析更多的时间。为此,需要将无序数据(messy data)整理成可供计算机程序识别与处理的、具备特定格式的数据,即整洁数据,其基本特征有三:
1.每列为一个变量(Each variable is in a column);
2.每行为一个观测(Each observation is in a row);
3.每个单元格为一个取值(Each value is a cell)。
这些特征在后面的例子中会逐一呈现,这里暂不展开。分析者获得的数据有些本身就适宜软件分析,但很多时候并非如此。使用tidyverse 包,可高效地将无序数据转为整洁数据,以便软件分析。
2.安装与加载
安装tidyverse 包,即可一次性安装多个系列包。具体如下:
此命令将安装如下包:
最常用数据分析包:
ggplot2,用于数据可视化
dplyr,用于数据操纵
tidyr,用于数据整洁
readr,用于读入R 格式数据
purrr,用于编程
tibble,用于形成便于数据处理的数据框
数据操纵类:
stringr,用于处理字符串数据
lubridate, 用于处理日期和时间数据
forcats,用于处理因子数据
数据导入类:
DBI,用于联接数据库
haven,用于读入SPSS、SAS、Stata 数据
httr,用于联接网页API
jsonlite,用于读入JSON 数据
readxl,用于读入Excel 文档
rvest,用于网络爬虫
xml2,用于读入xml 数据
数据建模类:
modelr,用于使用管道函数建模
broom,用于统计模型结果的整洁
安装成功后,可通过常规方式加载tidyverse 包,结果如下:
library(tidyverse)
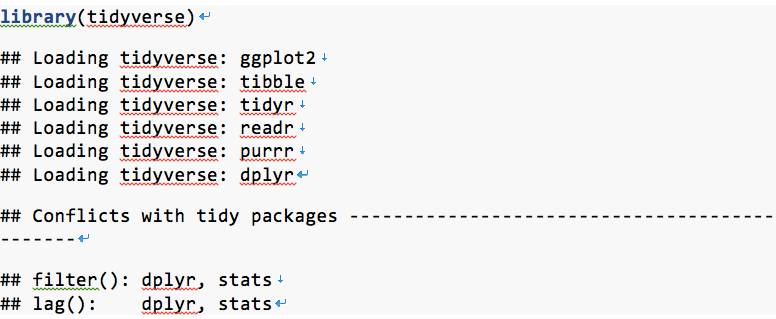
此时加载的是最常用的数据分析包,如ggplot2、dplyr、tidyr 等。若需其他tidyverse 包,可再单独导入。
若要查看此中的相关包是否为最新版本,可通过如下命令:
此时若出现相关更新提示,可遵照执行。
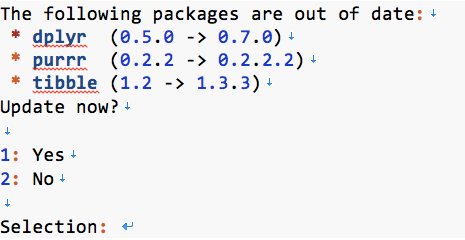
在Selection后键入1即可更新相关包。
开始数据分析时,不论是否用到,可先加载tidyverse 系列包,以便后续工作。此后将对此系列包中的重点R 包展开详细介绍。
最后一次修改于 2020-02-13